Chapter 18. Documentation¶
Unix の最初の用途は 1971 年、文書作成のプラットフォームとしてであった。Bell Labs が出願用の特許文書を作成するために使用した。1973 年に Joe Ossana の troff(1) が誕生してから何年もの間、その技術状況を明確にさせてきた。
それ以来、文書整形、組版、ページレイアウトプログラムは Unix の伝統の中で重要な主題となってきた。Unix の開発者と道具は今日、WWW の出現によって引き起こされた、文書作成の実践における広範囲にわたる変化の最先端にある。
Documentation Concepts¶
"What You See Is What You Get" (WYSIWYG) 文書作成プログラムとマークアップ中心のツールの違いを検討する。
WYSIWYG:
- GUI を有する。
- 入力内容は、最終的な印刷版に近くなるように描かれた、画面上の文書表示に直接挿入 される。
マークアップ中心:
- 文書は制御タグを含む平坦なテキスト。
- マークアップされたソースは普通のテキストエディターで編集可能。
- 印刷や画面用描画のためには、整形プログラムが必要。
WYSIWYG 方式は初期の計算機ハードウェアには高価過ぎたため、1984 年に Macintosh PC が登場するまでまれな存在だった。一方、Unix 生え抜きの文書ツールはほとんどすべてマークアップ中心だ。1971 年の Unix の troff(1) はマークアップ整形プログラムで、おそらく今でも使われている最古のものだろう。
WYSIWYG の実際の実装はさまざまな点で壊れがちであるため、マークアップ中心のツールにはまだ役割がある。
WYSIWYG 文書処理ツールには GUI に関する一般的な問題 (Chapter 11) がある。何でも視覚的に操作できるということは、何でも視覚的に操作しなければならないということになりがちだ。
WYSIWYG 文書プロセッサーは正確には WYSIWIG ではない。 ほとんどのインターフェイスは画面表示と印刷出力の違いを、実際にはなくすことなく曖昧にしている。つまり、インターフェイスの視覚的な側面によって、タイプライターではないにもかかわらず、タイプライターのようにプログラムを使うように促され、入力が予期せぬ望ましくない結果を生み出すことがある。
WYSIWIG システムは実際にはマークアップコードに依存しているが、通常の使用ではそれを見えないようにするために多大な努力をしている。つまり、マークアップのすべてを見ることができないので、マークアップコードの見当違いで壊れた文書を修正するのが難しいのだ。
WYSIWYG 文書プロセッサーは 300 ページの原稿のレイアウトを全体的に変更する必要がある場合、窮屈になりがちだ。
WYSIWYG users faced with that kind of challenge must give it up or suffer the death of a thousand mouse clicks;
このような状況ではマークアップを編集できることに代わるものはない。
今日、文書の体裁と構造的マークアップを区別することが一般的になっている。前者は、文書がどのように見えるべきかについての指示であり、後者は、文書がどのように構成され、何を意味するかについての指示だ。
体裁準位のマークアップは文書自体のすべての整形情報が伝わる。構造マークアップシステムでは、文書はスタイルシートと組み合わされなければならない。スタイルシートは、ドキュメントの構造マークアップを物理的なレイアウトにどのように変換するかを指示するものだ。
Macros are user-defined commands that are expanded by text substitution into sequences of built-in markup requests.
マークアップ中心の文書システムのほとんどはマクロ機能を支援している。通常、これらのマクロはマークアップ言語に構造的な機能(節の見出しを宣言する機能など)を追加する。
Mike Lesk: マクロセットは整形偏向の編集から内容重視の編集へと人々を押しやるために設計したものだ。どのマクロも、一つの文書を作成し、その体裁を統制することに集中していた人々に負けた。Web ページが読者と著者のどちらが体裁を統制すべきかという論争で泥沼にはまるのとちょうど同じだ。私は .AU (author) コマンドを斜体を得るためだけに使っている秘書をよく見かけた。
Note
負けてしまったが、昔の HTML 編集技法を思い出させる証言だ。
小さな文書(手紙や小冊子など)でやりたいことと、大きな文書(書籍や技術論文など)でやりたいことには大きな違いがあることに注意したい。大規模な文書は、より多くの構造を持ち、別々に変更しなければならない部分からつなぎ合わされ、目次のような自動的に生成される機能を必要とする傾向がある。どちらの性質もマークアップ中心の道具が好ましい。
The Unix Style¶
Unix 式の文書作成(およびその道具)には、技術的、文化的な特徴がいくつかあり、他の場所でのそれとは異なっている。これらの特徴を理解することで、次を理解するための文脈を作れ:
- なぜプログラムや実践がそのように見えるのか
- なぜ文書がそのように読めるのか
The Large-Document Bias¶
Unix 文書作成道具は大規模で複雑な文書を作成する想定で設計されてきた。その結果、 Unix 開発者はマークアップ中心の道具を愛するようになった。当時の PC 使用者とは異なり、Unix 文化は WYSIWYG 道具に感心しなかった。
中身の見えない、特に専売バイナリー形式に対する嫌悪感も WYSIWYG 道具の拒絶に一役買った。
Unix のプログラマーたちはその言語文書が利用可能になるとすぐに PostScript を熱狂的に利用した。最近のオープンソースの Unix システムには優れた PostScript と Portable Document Format (PDF) 道具がある。
Unix の文書作成道具は、画像を含めるための援助が比較的弱く、図や表、グラフ、数学的な組版、つまり技術論文でしばしば必要とされる種類のものを強力に支持する傾向がある。
Unix の比較的原始的な CLI スタイルが多くの点で GUI よりも有能使用者の必要に適しているように、troff(1) のような道具のマークアップ中心の設計は WYSIWYG プログラムよりも有能執筆者の必要に適している。
WWW の発展により、1993 年頃から、文書を複数のメディアで(少なくとも印刷物と HTML の両方で)表示する能力が中心的な課題となった。同時に、HTML の影響を受けて、一般人もマークアップ中心のシステムを使いこなすようになった。これは、1996 年以降の構造的マークアップへの関心の爆発と XML の発明に直接つながった。
2003 年半ばの今日、構造的マークアップを使用する XML ベースの文書道具の最先端の開発のほとんどは Unix の下で行われている。しかし同時に、Unix 文化は体裁準位のマークアップシステムという古い伝統を手放していない。HTML と XML は troff を部分的にしか駆逐していない。
Cultural Style¶
ほとんどのソフトウェア文書は知識のある人が知識のない人のために書いている。Unixシステムに同梱される文書は伝統的にプログラマーが仲間のために書いてきた。同業者間の文書でない場合でも、Unix システムに同梱されている膨大な量のプログラマー間の文書から、スタイルやフォーマットにおいて影響を受ける傾向がある。
Unix のマニュアルページには伝統的に BUGS という節がある。Unix の文化では仲間同士がソフトウェアの既知の欠点を詳細に説明し合うので、使用者は短いながらも有益な BUGS 節を質の高い作業の励みになると考える。
BUGS 節を抑えたりするような商用 Unix 頒布は必ず衰退していく。
一流の Unix 文書は電信的でありながら完全であるように書かれている。この流儀は自信があるがっついた読者を想定している。
Unix プログラマーは参照文を書くのが得意な傾向があり、ほとんどの Unix 文書は、それを書く人と同じように考えているけれども、まだそのソフトウェアの専門家ではない人に助言を述べるような趣がある。その結果、実際よりもずっと不可解で疎かに見えることがよくある。
Read every word carefully, because whatever you want to know will probably be there, or deducible from what's there. Read every word carefully, because you will seldom be told anything twice.
The Zoo of Unix Documentation Formats¶
最新のものを除くすべての主要な Unix 文書形式はマクロパッケージによって支援される体裁準位のマークアップだ。以下、それらを古いものから新しいものへと見ていく。
troff and the Documenter's Workbench Tools¶
Chapter 8 も見ろ。
troff は体裁準位のマークアップ言語を解釈する。GNU groff(1) のような最近の実装では、既定で PostScript を出力する。
Note
Example 18.1 の内容などは、テキストファイルに保存して次のコマンドで PDF に変換できる:
console
groff example.txt > example.ps
ps2pdf example.ps
素の troff で書かれた文書はほとんどない。troff はマクロ機能を支援しており、半ダースのマクロパッケージが多かれ少なかれ一般的に用いられる。これらのうち、圧倒的に一般的なのは、Unix のマニュアルページを書くために使用される man(7) マクロパッケージだ。
nroff(1) と呼ばれる troff(1) のより重要でない亜種は行印刷装置やキャラクターセル端末のような、定幅字体しか支持できない機器用の出力を生成する。端末ウィンドウで
Unix のマニュアルページを表示する場合、それを描くのは nroff だ。
Documenter's Workbench の道具群は、そのために設計された技術文書作成の仕事をよくこなし、計算機の能力が千倍にもなったにもかかわらず、三十年以上も使い続けられてきたのだ。
しかし、いくつかの点でひどく落ち込んでいる。最も深刻な問題はマークアップの多くが体裁準位であるため、修正されていない troff ソースから良い Web ページを作るのが難しいということだ。
TeX¶
TeX は Emacs エディターと同様、Unix 文化の外で生まれたが、今では Unix 文化に帰化している有能な組版プログラムだ。著名な計算機科学者である Donald Knuth が 1970 年代後半に、特に数学の組版の質の低さに焦りを感じたときに作ったものだ。
- troff(1) と同様、マークアップ中心。
- 言語は
troffよりも強力で、特に画像やページ位置の正確な内容、国際化などの処 理に優れている。 - 特に数学的な組版が得意で、文字詰め、行間詰め、分綴といった基本的な組版作業では 群を抜いている。
- ほとんどの数学専門誌の標準投稿形式となっている。
- American Mathematical Society の作業集団によってオープンソースとして管理されて いる。
- 科学論文にもよく用いられる。
troff(1) と同様、人間は通常、生の TeX マクロを手で大量に書くことはしない。ある特定のマクロパッケージである LaTeX はほとんど普遍的であり、TeX で編集していると言う人のほとんどは、実際には LaTeX を書いているという意味であることがほとんどだ。
TeX の重要な用途の一つは、通常使用者には見えないが、次のような他の文書処理ツールでは、PostScript を生成するよりも LaTeX を生成して PostScript に変換することが多い:
- xmlto(1)
- XML DocBook
TeX は troff(1) よりも応用範囲が広く、ほとんどの点でより優れた設計だ。
TeX は Web 中心の世界において troff と同じ根本的な問題を抱えている。マークアップは体裁準位で強い結びつきがあり、TeX ソースから優れた Web ページを自動的に生成することは難しく、欠陥が生じやすい。
TeX が Unix システム文書に使われることはないし、アプリケーション文書に使われることもまれだ。
Texinfo¶
Texinfo は Free Software Foundation が考案した文書マークアップで、主に GNU プロジェクトの文書に用いられている。Emacs や GCC などの重要な道具の文書もそうだ。
Texinfoは、紙への組版出力と閲覧用のハイパーテキスト出力の両方を支持するように特別に設計された最初のマークアップシステムだ。ただし、ハイパーテキストの形態は HTML ではなく info と呼ばれるもっと原始的なもので、もともとは Emacs の中から閲覧できるように設計されていた。印刷側では、Texinfo は TeX マクロに変換され、そこからPostScript に変換することができる。
2003 年半ば現在、Free Software Foundation は試行錯誤的な Texinfo から DocBook への翻訳に取り組んでいる。
POD¶
Plain Old Documentation は Perl の保守者が使用しているマークアップシステムだ。これはマニュアルページを生成し、体裁準位の~。
HTML¶
Unix プロジェクトでは少ないながらも HTML で直接文書を書く割合が増えてきた。この方法論の問題は HTML から高品質の組版出力を生成するのが難しいことだ。索引を生成するのに必要な情報が HTML には存在しないのだ。
DocBook¶
DocBook は大規模で複雑な技術文書用に設計された SGML と XML の文書型定義だ。純粋に構造的であるという点で、Unix 共同体で使われているマークアップ形式の中では唯一のものだ。
Chapter 14 で述べた xmlto(1) は、HTML, XHTML, PostScript, PDF, Windows Help マークアップ、等々の形態への変換を支援している。
主要なオープンソースプロジェクトのいくつかはすでに主形式として DocBook を使っている。本書は XML-DocBook で書いた。
The Present Chaos and a Possible Way Out¶
Unix 文書は今のところメチャクチャだ。
最近の Unix システム上の文書元帳ファイルは異なるマークアップ形式、man, ms, mm, TeX, Texinfo, POD, HTML, DocBook の間でばらついている。すべての描写処理版を見る一定の方法はない。Web アクセスもできないし、相互索引もない。
Unix 共同体の多くの人々はこの問題を認識している。彼らは市販の Unix の開発者たちよりも、技術的な背景を持たない末端使用者に受け入れられるかどうかを競うことに積極的だ。2000 年以降、文書交換形式として XML-DocBook を使用する方向に進んでいる。
システム全体のドキュメント登録装置として機能するソフトウェアを Unix システムすべてに搭載することが最終目的となる。システム管理者がパッケージをインストールするとき、そのパッケージの XML-DocBook 文書を登録装置に入力することが一つの段階になるだろう。その後共通の HTML 文書木に処理され、すでに存在する文書に相互参照が付く。
次に DocBook とそのツールチェーンについて詳細に見ていく。Unix での XML の入門として、実践のための手引として、主要な事例研究として読める。
DocBook¶
DocBook とそれを支持するプログラムには多くの混乱がつきまとう。DocBook の信奉者たちは、マークアップを書いたり、そこから HTML や PostScript を作ったりするために必要なこととはまったく関係のない略語を乱発し、計算機科学の基準から見ても濃密で難解な言葉を話している。XML の標準や技術論文はわかりにくいことで有名だ。
Document Type Definitions¶
DocBook は XML の方言だ。DocBook 文書は構造的なマークアップに XML タグを使った XML の一片だ。
例えば、章見出しを物理的に適切に整形するためには、本の原稿は通常、前見出し、章立て、後見出しで構成されていることを知る必要がある。このようなことを知るためには、 Document Type Definition (DTD) を与える必要がある。DTD は文書構造の中にどのような要素をどのような順序で入れることができるかを組版ソフトに伝える。
DocBook を XML の「方言」と呼んでいるのは、実際には DocBook が DTD であるということだ。
DocBook の背後には検証構文解析器と呼ばれるプログラムが潜んでいる。DocBook 文書を整形するとき、最初の段階はこのプログラムに通すことだ。これは与えられた文書を DocBook DTD と照らし合わせて、DTD の構造規則に違反していないことを確認する。
エラーがなければ、検証構文解析器は文書を XML 要素とテキストのストリームに変換し、構文解析器のバックエンドがスタイルシートの情報と組み合わせて整形された出力を生成する。
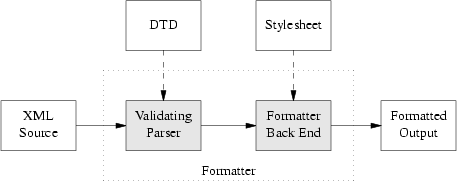{kind=link}
- 図式中の中央二つの箱が本書で言うツールチェーンだ。
- 組版ソフトに対する隠れた入力二つ、DTD とスタイルシートを忘れるな。
Other DTDs¶
他の DTD について簡単に触れておくと、前の節のどの部分が DocBook に特有で、どの部分が構造マークアップ言語のすべてに一般的なのかが明確になる。
TEI (Text Encoding Initiative) は主に文学的な文章の計算機転写のために学界で使用されている大規模で精巧な DTD だ。TEI の Unix ベースのツールチェーンは DocBook と同じツールの多くを用いるが、スタイルシートは異なる。
HTML の最新版である XHTML もまた、DTD によって記述される XML アプリケーションだ。
Note
XHTML に関する記述は全部無視していい。
その他にも、生命情報科学や銀行業など多様の分野で、構造化された情報を交換するための XML DTD が数多く整備されている。
The DocBook Toolchain¶
DocBook の原稿から XHTML を作成するには、xmlto(1) フロントエンドを通常用いる。次の例では、XML DocBook 文書から XHTML ファイルを複数出力する。索引ページ用のファイルと最上位節それぞれのページ用ファイルを含む:
xmlto xhtml source.xml
単一の巨大ページを作るのも可能だ:
xmlto xhtml-nochunks source.xml
印刷用の PostScript の作り方はこうだ:
xmlto ps source.xml
文書を HTML や PostScript に変換するには、DocBook DTD と適切なスタイルシートの組み合わせを文書に適用できるエンジンが必要だ。Figure 18.2 を見ろ。
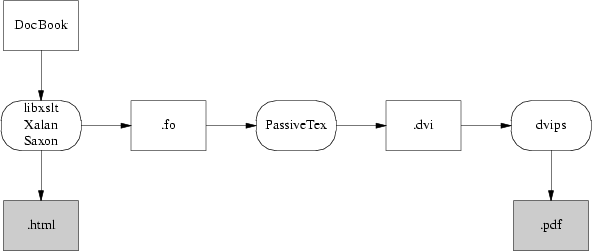{kind=link}
エンジン:
- libxslt
- Xalan & Saxon
Note
よく使う xsltproc が文書の解析とスタイルシート変換の適用を行うものであることが理解できた。
HTML への翻訳はかなり単純なスタイルシートを適用することで行われ、それで話は終わる。RTF もこの方法で生成するのは簡単で、XHTML や RTF から、いざというときにフラットな ASCII テキスト近似を生成するのは容易だ。
厄介なのは印刷だ。高品質の印刷出力、つまり PDF を生成するのは難しい。それを正しく行うには、内容から体裁段階と移行する人間の植字工の繊細な判断をアルゴリズムで複製する必要がある。
スタイルシートとして、DocBook マークブックを XML の一種である FO に変換するものを用いる。FO マークアップは非常に体裁段階のもので、XML の機能的な troff のようなものと考えられる。これを PDF にパッケージするために PostScript に翻訳したい。
Red Hat Linux に同梱されているツールチェーンでは、この作業は PassiveTeX という
TeX マクロパッケージによって処理される。これは xsltproc によって生成された整形オブジェクトを Donald Knuth の TeX 言語に変換する。DVI 形式として知られる TeX の出力はその後 PDF に加工される。これを模式化するとこうなる:
XML → TeX → DVI → PDF
字体は重要な問題だ。XML, TeX, PDF では字体の動作モデルがまったく異なる。また、国際化と地域化の扱いは悪夢だ。このコード経路の唯一の長所は、それが機能するということだ。
上品な方法は Apache プロジェクトが開発した FO から PostScript への直接変換器である FOP であろう。FOP を使えば、国際化の問題は解決しないまでも、少なくともうまく限定することができる。XML ツールは FOP に至るまで一貫して Unicode を扱う。 Unicode 文字から PostScript 字体への写像も FOP の問題だ。
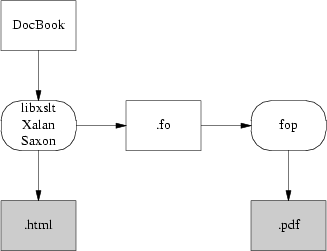{kind=link}
xsl-fo-proc と呼ばれる別のプロジェクトは、FOP と同じことを C++ で行うことを目指している。
Note
このプロジェクトを探したが所在不明。
Migration Tools¶
古い流儀の体裁マークアップを DocBook に変換するのに必要な労力が第二の問題だ。人間ならば文書の体裁を論理構造に解析することが通常可能だ。なぜなら、例えば、斜体の字体が「強調」を意味するときと、「これは外国語の句だ」といった別の意味を持つときを見分けるのに文脈を知っているからだ。
文書を DocBook に翻訳する際にはこの種の区別を明示する必要がある。古いマークアップに存在することもあるが、そうでないことも多く、欠けている構造情報はなんとかしなければダメだ。
次の翻訳ツールはどれも完全な仕事はしてくれない。翻訳後は検査と人手による編集が必要になるだろう。
- GNU Texinfo:
makeinfo --docbook - POD: モジュール
POD::DocBookは POD マークアップを DocBook に翻訳する。 - LaTeX: PassiveTeX の作者によれば、TeX4ht というプロジェクトは LaTeX から DocBook を生成できる。
manページとその他のtroffベースのマークアップ
四番目が最も厄介な問題。著者は troff を DocBook に翻訳する道具を書いた。これは
man(7), mdoc(7), ms(7), me(7) マクロから SGML または XML DocBook に翻訳する。
Editing Tools¶
2003 年半ばの現在、SGML/XML 文書用の優れたオープンソースの構造エディターがない。
Note
何を以て XML の優れたエディターとするかを定義したい。
LyX は印刷に LaTeX を使用し、LaTeX マークアップの構造編集を支持する GUI ワープロだ。DocBook を生成する LaTeX パッケージと LyX GUI で SGML, XML を書く方法を説明する how-to 文書がある。
Note
リンク先のスクリーンショットを見る限り、数式も GUI 的に編集可能らしい。
GNU TeXmacs は数式表示を含む技術的・数学的資料に適したエディターを作成することを目的としたプロジェクトだ。XML の支援計画があるが、まだそこに至っていない。
Note
リンク先の概要を見る限り、XML 形式で保存可能であることは謳っている。
Most people still hack DocBook tags by hand using either vi or emacs.
これは現代でも変わらない気がする。Visual Studio Code でアウトライン表示くらい?
Related Standards and Practices¶
DocBook 自体は手段であって目的ではない。 検索可能な文書データベースという目的を達成するためには DocBook 以外の標準も必要になる。文書目録とメタデータだ。
ScrollKeeper プロジェクトはこの要望に直接応えることを目的としている。
ScrollKeeper は Open Metadata Format を使用している。これは図書館のカードカタログシステムに似た、オープンソース文書を索引にするための標準だ。この発想とは、文書の原稿だけでなく、カードカタログのメタデータを使用する贅沢な検索機能を支援することだ。
SGML¶
XML には SGML (Standard Generalized Markup Language) という兄がいた。
XML-DocBook References¶
DocBook の学習を難しくしていることの一つは、DocBook 関連のサイトが W3C 標準の長い一覧や SGML 神学の膨大な練習問題、抽象的な用語の密集した藪などで初心者を圧倒しがちなことだ。
- XML in a Nutshell: 一般的な入門書。
- DocBook: The Definitive Guide: 確かに信頼がおける資料だが、入門書と しては最悪だ。
- Writing Documents Using DocBook: 代わりにこれを読め。
- DocBook FAQ: 消失
- DocBook wiki: 消失
- The XML Cover Pages: 消失
Best Practices for Writing Unix Documentation¶
Unix 文化圏の人々のために文書を書くときは読者を安く見てはいけない。バカ向けに書いているかのごとく書くと、筆者自身そうだとみなされる。
通俗化ととっつきやすくすることはまったく違う。前者が怠惰で重要なことを省略しているのに対し、後者は注意深い考えと断乎とした編集を要する。
分量を品質と勘違いしてはならない。そして特に、混乱を招くからといって機能的な詳細を省略したり、悪い印象を与えたくないからといって問題点についての警告を省略したりすることはしてはいけない。
情報密度の両極端のどちらに走るのも良くない。
画面写真の使用は控えめにしろ。インターフェイスのスタイルや感触以上の情報はほとんど伝わらない傾向がある。明確なテキストによる説明を代用できない。
プロジェクトがそれなりの規模になれば、おそらく三種類の文書を出荷するはずだ:
- 参考資料 man ページ
- 入門者用手引
- FAQ 一覧
配布の中心となる Web サイトも用意して然るべきだ。
巨大な man ページは好意的に見られない。ページが大きくなってきたら参照用の手引書を検討する。man ページでは手引書へのポインターを入れたり、プログラムがどのように起動されるかの詳細を簡単に要約する。
ソースコードには README のような標準的なメタ情報ファイル (Chapter 19) を含めろ。
- マニュアルページは伝統的な Unix の読者のための伝統的な Unix 式のコマンド参照資料 であるべし。
- 入門者用手引書は非技術的な使用者向けの長文の文書であるべし。
- FAQ は進化する資料であるべし。
文書をオンラインにすることは、
- 自分のソフトウェアの存在を知っている潜在的な使用者や顧客が、それを読み、それに ついて学ぶことを容易にするという直接的な効果がある。
- 自分のソフトウェアが Web 検索で発見されやすくなるという間接的な効果もある。